Server Side Tagging vs. Tracking: Understanding the Difference
Server Side Tagging vs. Tracking: What do the terms mean and what's the difference?

Justus
owntag Founder
published March 16, 2025
Two terms frequently used in the tracking ecosystem are Server Side Tracking and Server Side Tagging. What’s the difference?
The short answer, which also applies to the content here on owntag.eu:
In most cases, the two terms are used interchangeably.
People typically mean Server Side Tagging (more on this below) or, more generally, any type of digital data collection where data isn’t sent directly from the user’s browser to its final destination.
For everyday purposes, that description is perfectly adequate, and you don’t need to worry about the nuances in most situations.
But if you want to be super-precise, you can distinguish between the two like this:
What is Server Side Tagging?
Tagging comes from the namesake “tags,” small units of tracking logic. Whenever a tag manager or similar tool that controls which tracking is triggered under which conditions is in use, we’re typically talking about tagging.
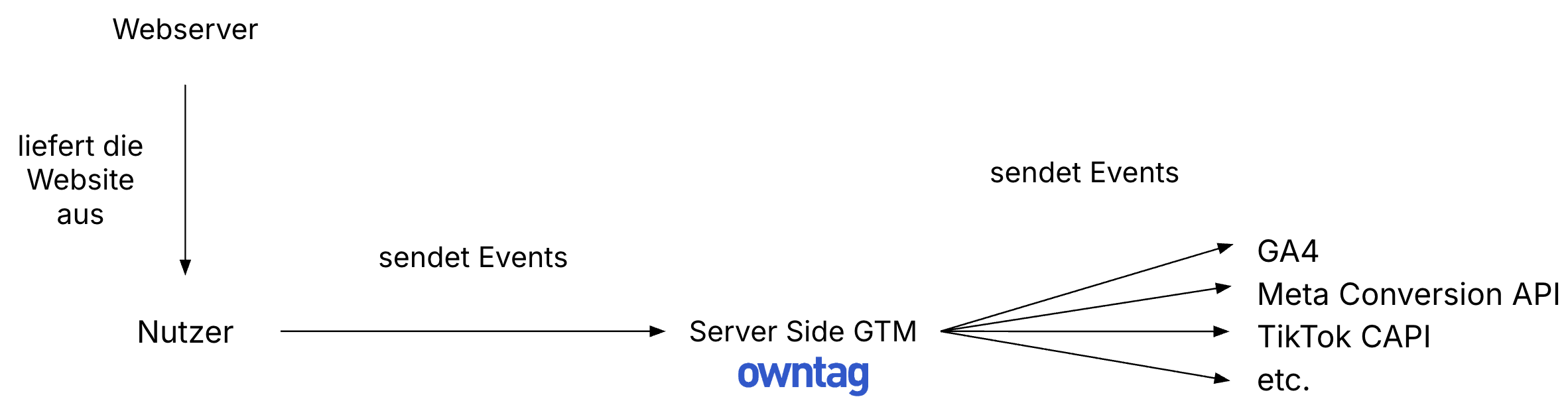
When this tagging happens on the server rather than in the browser, it’s Server Side Tagging.
Not always, but most of the time, data for Server Side Tagging is sent from the browser, arrives at a server-side tag manager, which then forwards it to its final destination.
Advantages
- The server-side tag manager operates independently from the systems that keep the website running. This makes it easier to give team members access to tagging without requiring them to learn the intricacies of the central infrastructure. Teams and processes become decoupled and can work more independently.
- Data can flow in both directions, meaning the tagging server can return information back to the browser. This is useful, for example, to make server-side stored values like a user’s customer lifetime value available for browser-side tracking or to enable personalization.
Disadvantages
- Browsers are prone to issues. They can be outdated, poorly programmed, limited by tracking restrictions, and often operate on slow internet connections. In such environments, capturing 100% of all theoretically trackable data isn’t always straightforward.
What is Server Side Tracking?
Server Side Tracking refers to a tracking process where data never reaches the user’s browser in the first place but is sent directly from the website’s server to its destination, such as a web analytics system or a marketing partner.
This principle inherently limits which data can be processed through Server Side Tracking: events that only occur in the browser cannot be tracked this way. The server delivering the website doesn’t detect clicks on UI elements, played YouTube videos, or time spent on the website and consequently can’t track them.
The term Server for the entity that both delivers the website and sends the analytics data should be understood very broadly in this context. It could be any number of things, such as:
- A CMS like WordPress, Typo3, etc., for example through a dedicated plugin
- A third-party hosted system like Shopify, Webflow, or Wix
- A custom-developed backend application, potentially based on a framework like Symphony, Nuxt, or Ruby on Rails
- A traditional web server in the narrower sense, e.g., Caddy or nginx
- CDN middleware like Cloudflare Workers or Bunny Edge Scripts
Advantages
- No browser-based tracking blocker can prevent your web server from sending data server-side.
- You can utilize more sophisticated transmission processes to ensure even more reliably that data reaches its destination 100% of the time. For example: A tracking request from the browser won’t be resent if it fails. On the server side, it’s easier to work with Message Queues, which can resend failed requests. Useful processes like logging, validation, etc., are also easier when you control the entire process chain from start to finish.
- Zero performance impact on the browser—the server handles all the tracking work.
Disadvantages
- Every backend is different, and each solution is quite individualized, meaning each project brings entirely new challenges.
- Without a server-side tag manager, there’s no convenient preview mode to easily analyze the sent data and debug problems.
- Quite a few data recipients necessarily require data from the browser, making them unsuitable for pure server-side tracking. GA4, for example, can receive server-side data via Measurement Protocol, but requires that these events be attached to a session previously initiated in the browser. Capturing all events of a session purely server-side isn’t supported.
The Blurring Lines
Whether a specific tracking setup is correctly categorized as Server Side Tagging or Tracking is often not clearly answerable in practice, as most cases utilize a combination of both:
Example 1: A fashion e-commerce shop sends GA4 events via Server Side GTM (Tagging).
The return rate is crucial in determining whether the business is profitable. If a customer later returns their package, the order is marked as returned in Shopify. Using Shopify Webhooks, this information goes directly from there as a refund event to GA4 (Tracking).
Example 2: The Meta Conversion API for a car dealership receives data from the browser via Server Side GTM (Tagging). However, the company’s most important conversion is the arrangement of a test drive, which is always scheduled by phone. After the call, customer service confirms the test drive, i. e. the conversion, in the CRM, which then directly sends a Lead event to Meta CAPI (Tracking).
Ready to go server-side?
Take control of your digital data collection with Server Side Tagging – easily and conveniently hosted with owntag.